What if you could force Stable Diffusion to draw a specific character, copy a pose exactly, or adopt any art style you want? Not through endless prompt tweaking or lucky randomness, but with precise, repeatable control that delivers exactly what you envision.
This is where most Stable Diffusion users hit a wall. They master basic prompting, generate decent images, but can’t achieve the consistency or precision needed for serious creative work. The images are close, but never quite right. The character style varies between generations. The pose is almost perfect, but not exact.
LoRAs and ControlNet change everything. They’re the difference between hoping Stable Diffusion understands your vision and commanding it to execute exactly what you want. These tools provide “god-level” control that transforms Stable Diffusion from a creative assistant into a precision instrument.
In this comprehensive guide, you’ll learn what LoRAs and ControlNet are, how to install them step-by-step, and how to use them to unlock creative possibilities that basic Stable Diffusion simply cannot achieve. Whether you’re creating consistent character art, copying specific poses, or applying signature art styles, you’re about to discover why these features make Stable Diffusion the preferred choice for professionals.
If you haven’t installed Stable Diffusion yet, start with our beginner’s guide to installing and using Stable Diffusion to get your environment set up. For context on why these features give Stable Diffusion a significant advantage, see our detailed comparison of Midjourney vs. Stable Diffusion’s advanced features.
Let’s unlock the true power of Stable Diffusion.
Part 1: LoRAs (Low-Rank Adaptation)
What is a LoRA? The Simple Explanation
Think of a LoRA as a small, specialized “plugin” for your main Stable Diffusion model. While your base model knows how to generate general images, a LoRA teaches it something very specific—a particular art style, a specific character’s appearance, a unique aesthetic, or even how to render specific objects or clothing.
The key advantage: LoRAs are tiny (typically 10-200MB) compared to full models (2-7GB), making them easy to download, store, and experiment with. You can apply multiple LoRAs to a single generation, mixing and matching different elements like building blocks.
Real-world examples of what LoRAs can do:
- Style LoRAs: Apply the exact art style of Studio Ghibli, cyberpunk aesthetics, watercolor paintings, or pixel art
- Character LoRAs: Generate consistent appearances of specific characters across multiple images
- Concept LoRAs: Master specific clothing styles, architectural elements, or visual effects
- Photography LoRAs: Replicate specific camera techniques, film stocks, or photography styles
Unlike trying to describe a complex style through lengthy prompts, a LoRA instantly applies that style with a single tag. It’s the difference between writing “in the style of Studio Ghibli animation with soft colors, pastoral landscapes, and whimsical character designs” versus simply adding <lora:ghibli_style:0.8>.
Where to Find and Download LoRAs
Civitai is the definitive hub for LoRAs and Stable Diffusion models. It’s a community-driven platform where creators share their trained LoRAs, complete with example images, recommended prompts, and usage instructions.
How to find quality LoRAs on Civitai:
- Visit Civitai.com and navigate to the Models section
- Filter by “LoRA” in the model type dropdown
- Sort by popularity or ratings to find well-tested, high-quality LoRAs
- Check the example images to see if the LoRA produces the style or character you want
- Read the description for recommended settings and trigger words
What to look for in a quality LoRA:
- Clear example images showing the LoRA’s capabilities
- Trigger words specified (keywords that activate the LoRA’s features)
- Recommended weight settings (typically between 0.6-1.0)
- Base model compatibility (check if it works with your Stable Diffusion version)
- User reviews and ratings indicating reliability
Pro tip: Start with popular, highly-rated LoRAs when learning. They typically have better documentation and more reliable results.
How to Install LoRAs in Automatic1111
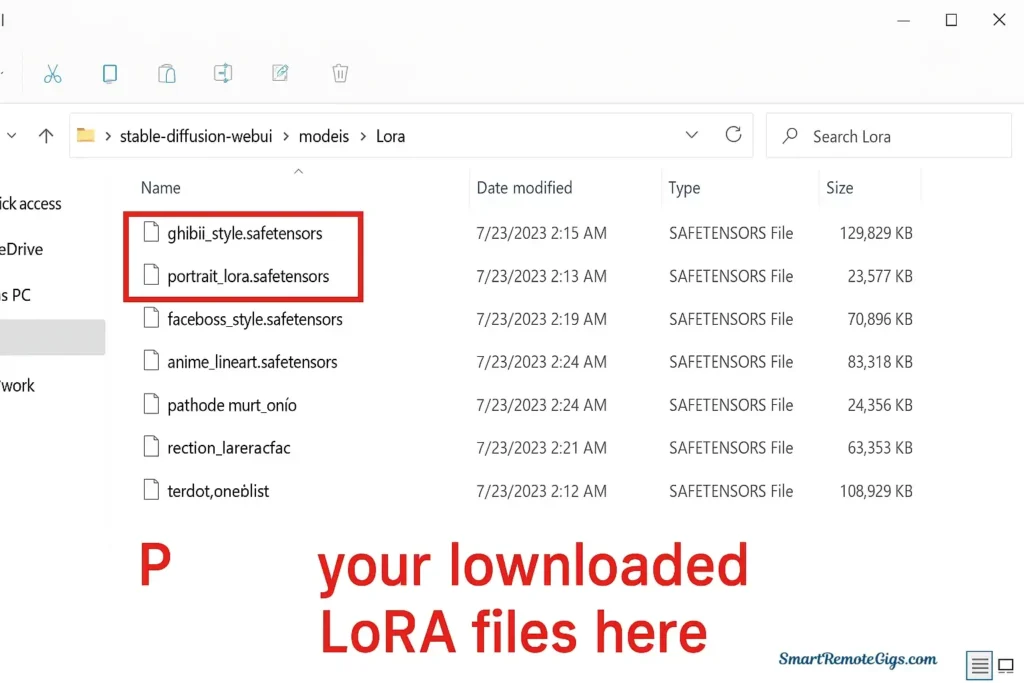
Installing LoRAs is remarkably simple—it’s just a matter of placing files in the correct folder.
Step-by-step installation:
- Download your LoRA from Civitai (the file will have a
.safetensorsor.ptextension) - Navigate to your Stable Diffusion installation folder, typically:
stable-diffusion-webui/models/Lora- Place the downloaded file directly into the
Lorafolder
- No extraction needed
- No configuration required
- The filename will be how you reference it in prompts
- Restart or refresh Automatic1111
- If the web UI is already open, click the refresh button (🔄) next to the LoRA selector
- Or restart the web UI completely
- Verify installation
- Click the 🎨 icon below the prompt box to open the LoRA browser
- Your newly installed LoRA should appear in the list
Organizing your LoRAs:
Create subfolders within the Lora directory to organize by category:
models/Lora/
├── styles/
├── characters/
├── photography/
└── concepts/When using LoRAs from subfolders, reference them as: <lora:styles/ghibli:0.8>
How to Use a LoRA in Your Prompt
LoRAs are activated using a specific syntax within your prompt. Understanding how to control their strength is crucial for optimal results.

The LoRA syntax:
<lora:filename:weight>Breaking it down:
- filename: The exact name of your LoRA file (without the .safetensors extension)
- weight: A number between 0 and 1 (sometimes up to 2) that controls how strongly the LoRA affects your image
0.5= subtle influence0.8= balanced application (recommended starting point)1.0= full strength1.2+= emphasized effect (may cause overfitting)
Basic example:
a portrait of a woman in a garden <lora:ghibli_style:0.8>Before & After Example:
Without LoRA:
Prompt: a cozy coffee shop interior, warm lighting, wooden furniture, plants
Result: Generic coffee shop with standard renderingWith Studio Ghibli Style LoRA:
Prompt: a cozy coffee shop interior, warm lighting, wooden furniture, plants <lora:ghibli_style:0.8>
Result: Same scene but rendered with Ghibli's signature soft colors, painterly quality, and whimsical atmosphereUsing multiple LoRAs:
a portrait of a warrior woman <lora:fantasy_armor:0.7> <lora:oil_painting:0.6>This combines a fantasy armor LoRA with an oil painting style LoRA, blending both effects.
Understanding trigger words:
Many LoRAs require specific trigger words to activate their features. These are keywords the LoRA was trained to recognize.
Example:
<lora:cyberpunk_city:0.8>, neon lights, cyberpunk style, futuristic buildingsThe trigger words “neon lights,” “cyberpunk style,” and “futuristic buildings” help activate the LoRA’s specific training.
Always check the LoRA’s description on Civitai for recommended trigger words and example prompts.
Pro tips for LoRA usage:
- Start with weight 0.8 and adjust up or down based on results
- Lower weights (0.5-0.7) for subtle style influences
- Higher weights (0.9-1.2) for character consistency or strong style application
- If results look distorted or “overcooked,” reduce the weight
- Experiment with combining complementary LoRAs for unique results
Part 2: ControlNet
What is ControlNet? The Simple Explanation
ControlNet is a guidance system that gives you unprecedented control over composition, pose, depth, and structure. Instead of hoping Stable Diffusion interprets your text prompt correctly, you provide a reference image, and ControlNet extracts specific information—like the exact pose of a person, the edges and composition of a scene, or the depth and perspective—and forces your generated image to follow that structure.
Think of it this way: Without ControlNet, you’re describing a photograph to someone and hoping they draw it correctly. With ControlNet, you’re showing them a blueprint and saying “follow this exact structure, but make it look like this.”
The magic of ControlNet:
- Copy poses precisely from reference photos or pose skeletons
- Maintain composition while completely changing the subject and style
- Preserve depth and perspective from architectural or landscape references
- Trace edges to maintain exact layout while transforming everything else
- Control lighting and normal maps for consistent 3D-like rendering
ControlNet doesn’t just influence your image—it provides strict structural guidelines that Stable Diffusion must follow while interpreting your creative prompt.
How to Install the ControlNet Extension
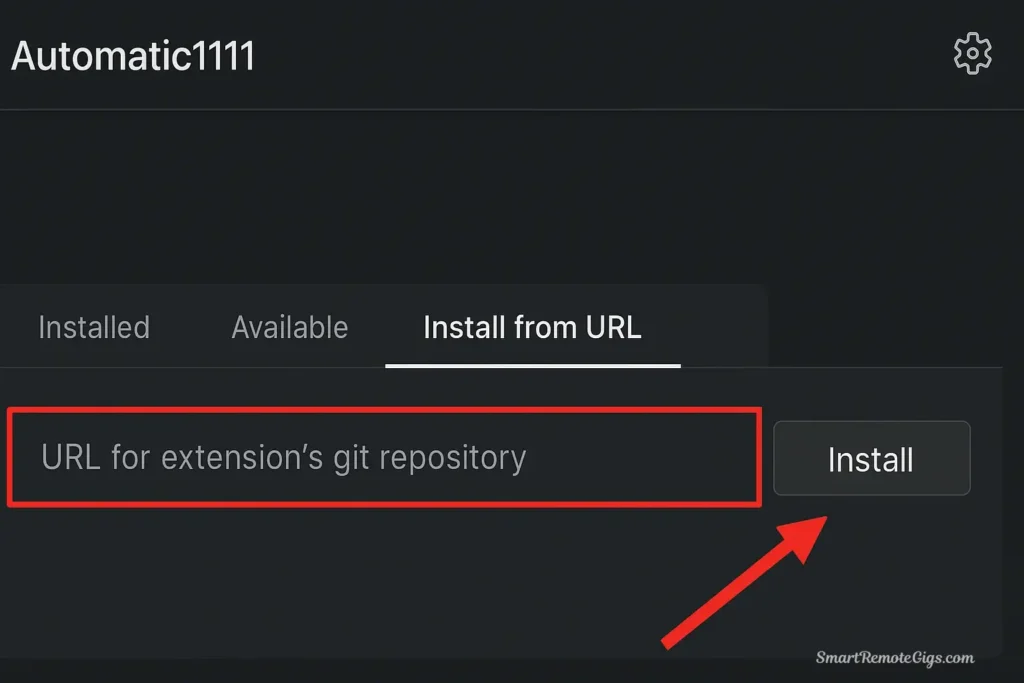
ControlNet is installed as an extension in Automatic1111, which means you’ll be adding functionality to your existing Stable Diffusion setup.
Step-by-step installation:
- Open Automatic1111 Web UI in your browser (typically
http://127.0.0.1:7860) - Navigate to the Extensions tab at the top of the interface
- Click “Install from URL” sub-tab
- Enter the ControlNet repository URL:
https://github.com/Mikubill/sd-webui-controlnet- Click “Install” and wait for the process to complete
- This may take several minutes
- The console window will show installation progress
- Go to “Installed” tab and click “Apply and restart UI”
- Verify installation:
- After restart, scroll down below the prompt box
- You should see a new “ControlNet” accordion section
- Click to expand it and confirm the interface appears
Downloading ControlNet models:
After installing the extension, you need to download the actual ControlNet models (the preprocessors and control models).
- Visit the ControlNet models page on Hugging Face or Civitai
- Download the models you need (we’ll cover the top 3 essential ones next)
- Files will be
.pth,.safetensors, or.ckptformat
- Place models in:
stable-diffusion-webui/extensions/sd-webui-controlnet/models- Refresh the ControlNet model list in the web UI
- Click the refresh button (🔄) next to the model dropdown
Troubleshooting installation:
- If ControlNet doesn’t appear, ensure you clicked “Apply and restart UI”
- Check the console for error messages during installation
- Verify you have enough disk space (models can be large)
- Some antivirus software may interfere—temporarily disable if needed
A Beginner’s Guide to the Top 3 ControlNet Models
ControlNet offers numerous models, but three stand out as essential for most creative work. Master these first before exploring advanced options.
1. OpenPose: Perfect Human Pose Control
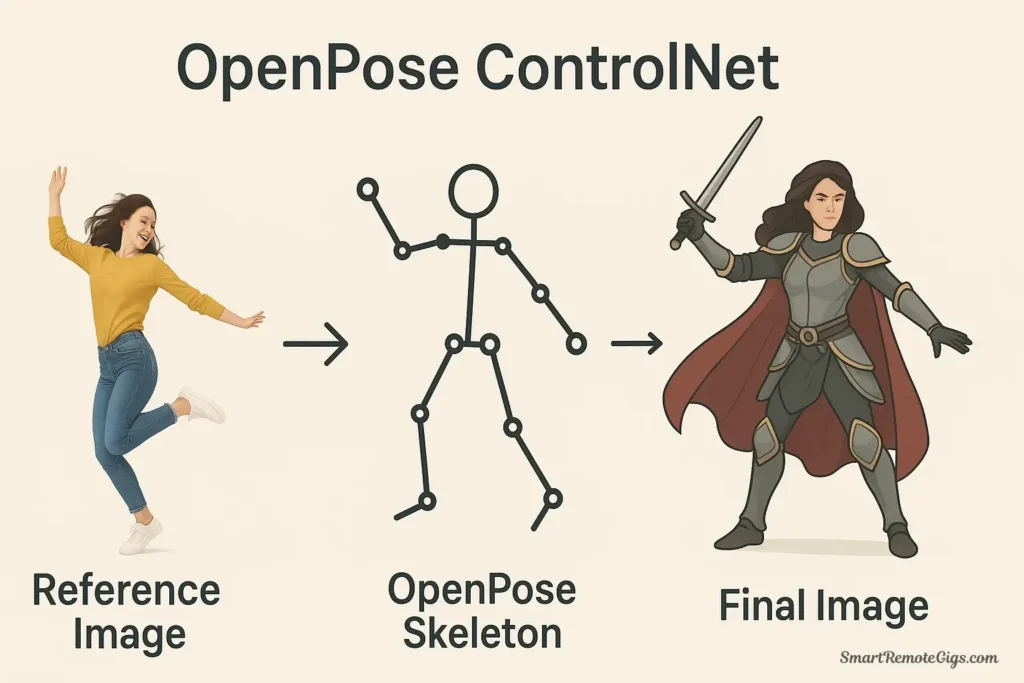
What it does:
OpenPose extracts the skeletal structure and pose from a reference image (or uses a pose skeleton you create), then forces your generated character to match that exact pose. It’s invaluable for character consistency, specific poses, and dynamic compositions.
Best used for:
- Copying poses from reference photographs
- Creating consistent character poses across multiple images
- Ensuring anatomically correct poses without prompt struggles
- Action scenes and dynamic character compositions
How to use OpenPose:
- Enable ControlNet by checking the “Enable” box in the ControlNet section
- Upload your reference image or pose skeleton
- Can be a photograph of a person
- Can be a stick-figure pose you create in pose editing software
- Can be an existing OpenPose skeleton image
- Select “OpenPose” preprocessor from the dropdown menu
- Select the matching control model (e.g., “control_openpose”)
- Set control weight (start with 1.0 for strict pose adherence)
- Write your prompt describing what you want the character to look like:
a female warrior in fantasy armor, detailed face, battlefield background- Generate and watch as your prompt is rendered in the exact pose from your reference
Example workflow:
- Reference: Photo of a person in a dynamic jumping pose
- Preprocessor: OpenPose extracts the skeleton showing joint positions
- Output: Your fantasy warrior in that exact jumping pose
Pro tips for OpenPose:
- Lower control weight (0.7-0.8) if the pose feels too rigid
- Use the “OpenPose Editor” extension to create custom poses from scratch
- Combine with a character LoRA for consistent character + consistent pose
- Hand and face details may need refinement—use inpainting for precision
2. Canny: Edge and Composition Control
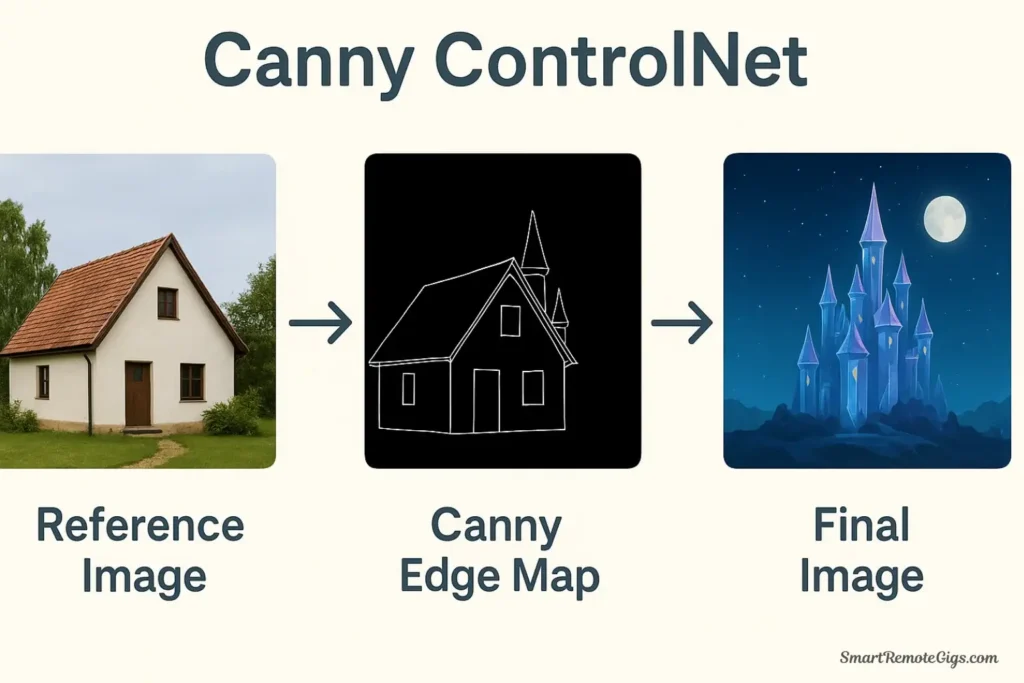
What it does:
Canny detects all the edges in your reference image, creating a line-art map that Stable Diffusion must follow. This maintains the exact composition, layout, and structural elements while allowing complete transformation of the subject matter and style.
Best used for:
- Maintaining composition from reference photos
- Transforming photographs into illustrations while keeping layout
- Architectural precision and structural accuracy
- Converting sketches or line art into fully rendered images
How to use Canny:
- Enable ControlNet in the interface
- Upload your reference image
- Works with photographs, drawings, or any image with clear edges
- Simpler compositions work better than cluttered scenes
- Select “Canny” preprocessor
- Adjust Canny threshold if needed (default usually works well)
- Lower threshold = more edge details captured
- Higher threshold = only strong edges
- Select “control_canny” model
- Set control weight (0.8-1.0 for composition adherence)
- Write your transformation prompt:
a fantasy castle in a mystical landscape, dramatic clouds, painted style- Generate with your original photo’s composition preserved
Example workflow:
- Reference: Photo of a modern building
- Preprocessor: Canny extracts all edges and structural lines
- Output: A fantasy castle with the exact same composition and perspective
Pro tips for Canny:
- Experiment with threshold values to control edge sensitivity
- Combine with style LoRAs for artistic transformations
- Works excellently for line art coloring
- Great for maintaining perspective in architectural work
3. Depth: 3D Structure and Perspective Control
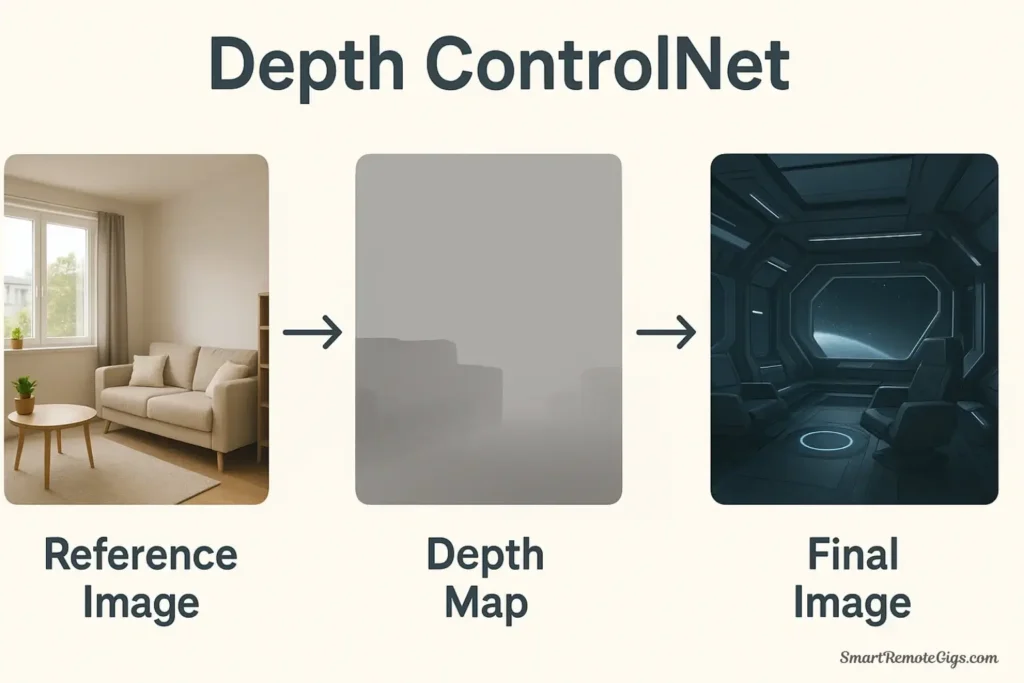
What it does:
Depth creates a depth map from your reference image, showing which parts are closer (lighter) and farther away (darker). This preserves the 3D structure, depth relationships, and perspective while allowing you to change everything else about the scene.
Best used for:
- Maintaining spatial relationships in complex scenes
- Preserving perspective and depth in architectural work
- Creating variations while keeping 3D structure consistent
- Ensuring proper foreground/background separation
How to use Depth:
- Enable ControlNet and expand the section
- Upload your reference image
- Works best with images that have clear depth variation
- Landscapes, interiors, and architectural scenes are ideal
- Select “Depth” preprocessor from the dropdown
- MiDaS is the most common depth estimator
- You’ll see a preview of the depth map (lighter = closer, darker = farther)
- Select “control_depth” model
- Set control weight (0.7-1.0 depending on how strict you want depth preserved)
- Write your scene transformation prompt:
a cozy library interior, wooden shelves, warm lighting, books everywhere- Generate and the depth structure will match your reference
Example workflow:
- Reference: Photo of a living room with clear depth
- Preprocessor: Depth map showing sofa (close), coffee table (medium), windows (far)
- Output: A fantasy throne room with the exact same depth relationships
Pro tips for Depth:
- Use lower weights (0.6-0.7) for more creative freedom with depth
- Excellent for maintaining consistent room layouts across variations
- Combine with Canny for ultra-precise architectural control
- Works well with interior design visualizations
ControlNet Settings Panel Explained
Understanding the ControlNet interface helps you get the most from these powerful tools.
Key settings in the ControlNet panel:
Enable: Checkbox to activate ControlNet for this generation
Preprocessor: The algorithm that processes your reference image
- “None” if you’re uploading a pre-processed image (like an existing pose skeleton)
- Select the appropriate preprocessor for your model (OpenPose, Canny, Depth, etc.)
Model: The actual ControlNet model that will guide generation
- Must match or be compatible with your preprocessor choice
- Download models separately and place in the models folder
Control Weight: How strongly ControlNet influences the output
- 1.0 = strict adherence to control image
- 0.5 = loose guidance, more creative freedom
- 1.5+ = very strict (may cause artifacts)
Starting/Ending Control Step: When ControlNet applies during generation
- Default 0 to 1 means ControlNet guides the entire process
- Adjust if you want ControlNet influence only during certain stages
Preprocessor Resolution: Quality of the preprocessed image
- Higher = more detail captured, but slower processing
- Default 512 works for most cases
Control Mode: How ControlNet balances with your prompt
- Balanced: Even weight between prompt and control
- My prompt is more important: Prioritizes text description
- ControlNet is more important: Prioritizes structural control
Combining Your Powers: Using LoRAs and ControlNet Together
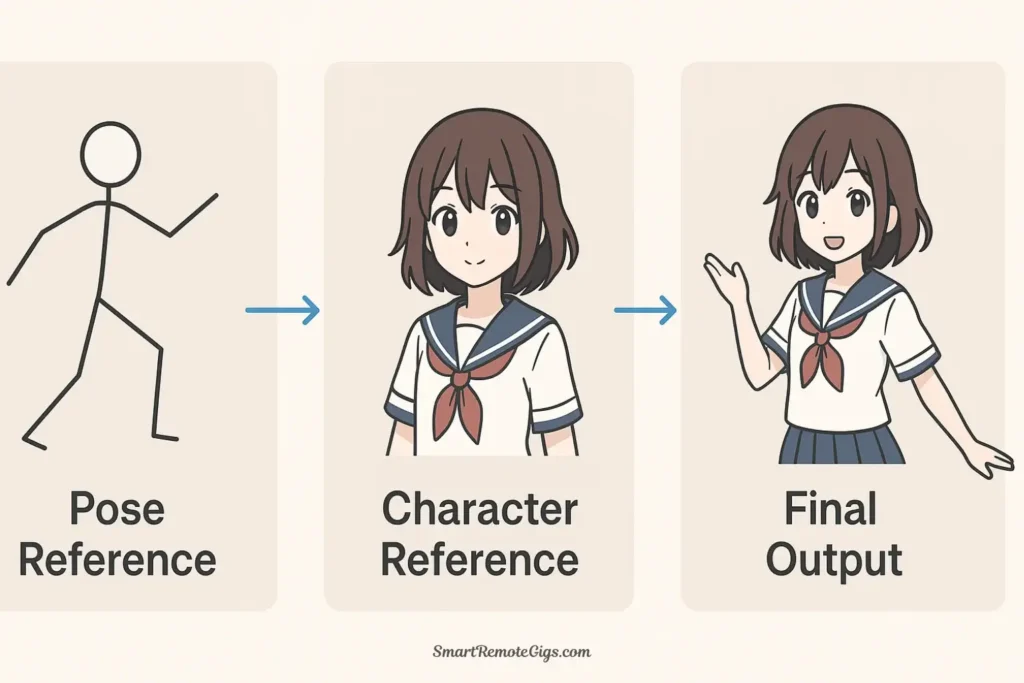
The true magic happens when you combine LoRAs and ControlNet. This gives you control over both what you’re generating (style, character, aesthetic via LoRA) and how it’s structured (pose, composition, depth via ControlNet).
Example: Creating a specific character in an exact pose
Goal: Generate your custom anime character (defined by a character LoRA) in a dynamic action pose (controlled by OpenPose ControlNet).
Step-by-step workflow:
- Find or create your pose reference
- Use a photo of someone in the pose you want
- Or create a pose skeleton using OpenPose Editor
- Set up ControlNet:
- Enable ControlNet
- Upload pose reference
- Select OpenPose preprocessor
- Select control_openpose model
- Set weight to 1.0
- Craft your prompt with LoRA:
masterpiece, best quality, solo, 1girl, warrior outfit, determined expression, outdoor background <lora:my_character:0.9>- Generate
Result: Your specific character (from the LoRA) in the exact pose (from ControlNet), with complete consistency.
Advanced combination example:
Scenario: Create a Studio Ghibli-style illustration of a specific room layout with a character in a precise pose.
Tools used:
- Depth ControlNet: Maintains room structure from reference photo
- OpenPose ControlNet: (Use Multi-ControlNet feature) Controls character pose
- Ghibli Style LoRA: Applies the signature Studio Ghibli aesthetic
- Character LoRA: Ensures consistent character appearance
Setup:
Prompt: a cozy bedroom, afternoon sunlight, peaceful atmosphere, 1girl sitting on bed reading <lora:ghibli_style:0.8> <lora:my_character:0.7>
ControlNet Unit 0 (Depth): Room reference photo, weight 0.8
ControlNet Unit 1 (OpenPose): Character pose reference, weight 1.0Result: A Studio Ghibli-style scene with your consistent character, in a precise pose, within an exact room layout.
Best practices for combining LoRAs and ControlNet:
- Layer your controls strategically:
- Use ControlNet for structure and composition
- Use LoRAs for style and specific elements
- Keep total LoRA weights under 2.0 to avoid conflicts
- Adjust weights for balance:
- If ControlNet is too dominant, reduce weight to 0.7-0.8
- If LoRA isn’t showing through, increase its weight
- Find the sweet spot through experimentation
- Use appropriate resolutions:
- Match your generation resolution to your ControlNet reference
- Higher resolution = more detail but slower generation
- Iterate intelligently:
- Generate multiple variations with same settings
- Adjust one variable at a time to understand its effect
- Save successful combinations for future use
Common powerful combinations:
| LoRA Type | + ControlNet | = Result |
|---|---|---|
| Character LoRA | OpenPose | Consistent character in exact poses |
| Style LoRA | Canny | Artistic transformation keeping composition |
| Photography LoRA | Depth | Photorealistic scene with controlled 3D space |
| Clothing LoRA | OpenPose | Specific outfits on precisely posed characters |
Advanced Tips and Tricks
Tip 1: Use Negative LoRAs for Better Control
Some LoRAs are trained specifically as “negative” embeddings to avoid certain features:
Prompt: beautiful portrait
Negative prompt: <lora:bad_hands:0.8>, <lora:bad_anatomy:0.6>These help fix common AI generation issues like malformed hands or anatomical errors.
Tip 2: Chain ControlNets for Complex Compositions
Use the “Starting/Ending Control Step” feature to apply different ControlNets at different stages:
- ControlNet 1 (Depth): Steps 0.0-0.6 (early composition)
- ControlNet 2 (OpenPose): Steps 0.3-1.0 (character refinement)
This creates a pipeline where spatial structure is established first, then character details are refined.
Tip 3: Create Style References with ControlNet
The “Reference” ControlNet model lets you use any image as a style reference without specific preprocessing:
- Upload your style reference image
- Select “reference_only” or “reference_adain” preprocessor
- Your generation will adopt the overall style and atmosphere
Perfect for matching existing artwork or photography styles.
Tip 4: Use LoRA Blocks for Fine Control
Advanced users can control which parts of the model the LoRA affects using LoRA Block Weight extension:
<lora:style:1:0,0,0,1,1,1,1,1,1,0,0,0,0,0,0,0,0>This controls influence across different layers, allowing ultra-precise style application.
Tip 5: Batch Process with Consistent ControlNet
For creating variations with consistent structure:
- Set up your ControlNet with reference image
- Use X/Y/Z plot script to test different prompts or seeds
- All variations maintain the same controlled structure
- Perfect for style exploration or character variations
Tip 6: Mix Preprocessor Results
Pre-process your reference image with multiple preprocessors separately, then blend them in an image editor:
- Combine Canny edges with Depth information
- Overlay OpenPose skeleton on Scribble sketch
- Create custom control maps for unique effects
Upload your blended control image and use “none” as preprocessor.
Tip 7: Save ControlNet Presets
In the ControlNet interface, you can save your settings configurations:
- Set up your perfect ControlNet configuration
- Click the “💾” (save) icon
- Load saved presets for consistent workflow
- Great for repeated use cases like character art or product shots
Troubleshooting Common Issues
Issue: LoRA has no visible effect
Possible causes and solutions:
- Weight too low: Increase from 0.5 to 0.8 or higher
- Missing trigger words: Check LoRA description for required keywords
- Incompatible base model: Ensure LoRA matches your checkpoint (SD 1.5 vs SDXL)
- LoRA not loaded: Refresh the LoRA list or restart WebUI
- Corrupted file: Re-download the LoRA
Issue: ControlNet producing distorted results
Solutions:
- Check preprocessor/model match: Ensure they’re compatible
- Adjust control weight: Try lowering to 0.6-0.8
- Verify reference image quality: Use clear, well-lit references
- Resolution issues: Match generation size to reference
- Update ControlNet: Older versions may have bugs
Issue: Out of memory errors with ControlNet
Solutions:
- Reduce generation resolution: Try 512×512 instead of 768×768
- Use fewer ControlNet units: Stick to one at a time
- Enable memory optimization: Add
--medvramor--lowvramto launch arguments - Close other applications: Free up system RAM and VRAM
- Update drivers: Ensure GPU drivers are current
- Consider cloud generation: Services like Google Colab for complex generations
Issue: Results too different from reference
Solutions:
- Increase control weight: Set to 1.2 or higher
- Extend control step range: Keep at 0.0-1.0 for full generation
- Simplify prompt: Remove conflicting descriptions
- Use stricter control mode: Select “ControlNet is more important”
- Check preprocessor preview: Ensure it captured your reference correctly
Issue: LoRAs conflicting with each other
Solutions:
- Reduce total weight: Keep combined weights under 2.0
- Remove incompatible combinations: Some style LoRAs don’t mix well
- Adjust individual weights: Balance by testing weights 0.5-0.8
- Use fewer LoRAs: Sometimes less is more
- Check training compatibility: Some LoRAs trained on different base models may conflict
Frequently Asked Questions
Can I use multiple LoRAs in one image?
Yes! You can use multiple LoRAs simultaneously by including multiple LoRA tags in your prompt:
<lora:style_one:0.7> <lora:style_two:0.5> <lora:character:0.9>However, keep in mind that using too many LoRAs or setting weights too high can cause conflicts or “overcooked” results. Start with 2-3 LoRAs maximum and adjust weights to find the right balance. The combined weight of all LoRAs should generally stay under 2.5 for best results.
What’s the difference between LoRAs and Textual Inversion embeddings?
Both add custom concepts to Stable Diffusion, but they work differently:
- LoRAs: Modify the model’s weights to teach it new styles or concepts. More powerful and flexible, with adjustable strength via weight parameters. Typically 10-200MB in size.
- Textual Inversion (Embeddings): Create new tokens/keywords that the model associates with specific concepts. Smaller files (10-100KB) but less powerful. Used simply by including the embedding name in your prompt.
When to use each:
- Use LoRAs for styles, characters, and significant visual changes
- Use embeddings for simple concepts, specific objects, or as negative embeddings to avoid certain features
Do I need a powerful GPU to use ControlNet?
ControlNet does require additional computational resources compared to basic Stable Diffusion generation, but it’s not drastically more demanding:
- Minimum: 6GB VRAM (GTX 1660, RTX 2060)
- Recommended: 8-12GB VRAM (RTX 3060, RTX 3080)
- Optimal: 12GB+ VRAM (RTX 3090, RTX 4090)
Tips for lower-end systems:
- Generate at lower resolutions (512×512 or 512×768)
- Use only one ControlNet unit at a time
- Reduce batch size to 1
- Close other applications to free up VRAM
- Consider using the
--medvramor--lowvramlaunch arguments
How do I know which ControlNet model to use?
Choose based on what aspect of your reference image you want to preserve:
| Model | Use When You Want To… |
|---|---|
| OpenPose | Copy human poses, body positioning, gesture |
| Canny | Preserve edges, composition, overall layout |
| Depth | Maintain 3D spatial relationships and perspective |
| Normal | Control surface angles and lighting direction |
| Scribble | Work from rough sketches or simple drawings |
| Lineart | Transform clean line art into full illustrations |
| Seg (Segmentation) | Preserve object placement and scene layout |
| Shuffle | Keep color palette while changing everything else |
For beginners, start with OpenPose (for characters), Canny (for composition), and Depth (for spatial structure). These three handle 90% of common use cases.
Where can I find more LoRAs and ControlNet models?
For LoRAs:
- Civitai – The largest repository with thousands of community-created LoRAs
- Hugging Face – Many professional and experimental LoRAs
- Discord Communities – Artists often share custom LoRAs in Stable Diffusion Discord servers
For ControlNet Models:
- Official ControlNet GitHub – Original models and documentation
- Hugging Face – lllyasviel’s official model releases
- Civitai – Community versions and fine-tuned variations
Always check compatibility with your Stable Diffusion version before downloading.
How do I create my own LoRA?
Training your own LoRA requires:
Requirements:
- A dataset of 15-100 images of your subject/style
- A GPU with at least 12GB VRAM (or use cloud training services)
- Training software (Kohya_ss, EveryDream2, or online platforms like Replicate)
Basic training process:
- Collect and prepare images – Consistent, high-quality images of your subject
- Caption your images – Describe what’s in each image
- Set training parameters – Learning rate, epochs, network rank
- Train the LoRA – Can take 30 minutes to several hours
- Test and refine – Generate samples and retrain if needed
For beginners:
- Start with online training platforms that handle the technical setup
- Use pre-configured training scripts like Kohya_ss GUI
- Join training-focused communities for guidance
Training your own LoRAs opens unlimited creative possibilities for custom styles and characters.
Can I use commercial/paid LoRAs in my projects?
License terms vary by creator:
- Free LoRAs on Civitai: Check each model’s license
- Some allow commercial use freely
- Others restrict commercial use
- Always read the license before commercial projects
- Paid/Premium LoRAs: Usually come with specific license terms
- Personal use vs. commercial use pricing may differ
- Some require attribution
- Check terms of service carefully
Best practice:
- Read the license information on each LoRA’s page
- When in doubt, contact the creator
- Keep records of licenses for commercial work
- Consider creating your own LoRAs for commercial projects to avoid licensing issues
Can I combine a LoRA with multiple ControlNets?
Absolutely! This is one of the most powerful techniques in Stable Diffusion:
Example combination:
Prompt: a female knight in ornate armor, castle courtyard, dramatic lighting <lora:fantasy_armor:0.8> <lora:oil_painting_style:0.6>
ControlNet Unit 0: OpenPose (character pose reference), weight 1.0
ControlNet Unit 1: Depth (environment structure reference), weight 0.7What this achieves:
- LoRA 1: Specific fantasy armor style
- LoRA 2: Oil painting aesthetic
- ControlNet 1: Exact character pose
- ControlNet 2: Precise environment depth and structure
Result: A character in your specific armor style, rendered as an oil painting, in an exact pose, within a precisely structured environment.
Limitations to watch for:
- More controls = longer generation time
- System requirements increase (need more VRAM)
- More complex to troubleshoot if results aren’t right
- Sweet spot is usually 2-3 LoRAs + 1-2 ControlNets
What’s the best way to organize my growing LoRA collection?
As you collect LoRAs, organization becomes crucial:
Folder structure recommendation:
models/Lora/
├── styles/
│ ├── anime/
│ ├── realistic/
│ ├── artistic/
│ └── photography/
├── characters/
│ ├── original/
│ └── fanart/
├── concepts/
│ ├── clothing/
│ ├── environments/
│ └── effects/
└── tools/
├── detail_enhancers/
└── quality_improvers/Naming conventions:
- Use descriptive names:
ghibli_style_v2notmodel_final - Include version numbers if you keep multiple versions
- Add creator name for attribution:
artist_style_by_creator
Documentation tips:
- Keep a text file with your favorite prompts for each LoRA
- Note optimal weight settings you’ve discovered
- Screenshot example outputs for quick reference
- Track which base models work best with each LoRA
Maintenance:
- Regularly delete LoRAs you never use
- Keep only the best version of similar LoRAs
- Test new LoRAs before adding to main collection
- Backup your curated collection regularly
Resources and Next Steps
Essential Communities
- r/StableDiffusion – Reddit community with tutorials and showcases
- Civitai Discord – Direct connection with LoRA creators
- Automatic1111 GitHub – Official support and issue tracking
- Stable Diffusion Discord – Large community for all skill levels
Recommended Learning Path
- Week 1: Master basic LoRA usage with 5-10 style LoRAs
- Week 2: Learn OpenPose ControlNet for character poses
- Week 3: Explore Canny and Depth for composition control
- Week 4: Combine LoRAs and ControlNet for complex projects
- Ongoing: Experiment with advanced techniques and new models
Tools and Extensions Worth Exploring
- Controlnet-M2M: Multi-ControlNet simplified workflow
- OpenPose Editor: Create custom pose skeletons
- LoRA Block Weight: Fine-tune LoRA influence by layer
- Dynamic Prompts: Automate prompt variations
- Ultimate SD Upscale: Enhance your final outputs
Where to Go From Here
You’ve now mastered the core tools that separate casual users from Stable Diffusion experts. Your journey continues with:
- Experiment relentlessly: Every generation teaches you something new
- Build your library: Curate LoRAs and reference images for your style
- Join the community: Share discoveries and learn from others
- Push boundaries: Combine techniques in ways nobody has tried
- Create your own: Eventually consider training custom LoRAs
The Stable Diffusion ecosystem evolves rapidly. New LoRAs, updated ControlNet models, and innovative techniques emerge constantly. Stay curious, keep experimenting, and remember: every expert started exactly where you are now.
Conclusion: You’ve Unlocked Stable Diffusion’s True Potential
Congratulations! You now understand the two most powerful features in Stable Diffusion’s arsenal:
LoRAs give you control over WHAT you generate:
- Apply any art style instantly with precision
- Create consistent characters across unlimited images
- Master specific aesthetics, concepts, and visual elements
- Mix and match multiple influences like creative building blocks
ControlNet gives you control over HOW you generate it:
- Copy poses exactly from any reference
- Maintain composition while transforming subjects
- Preserve depth and spatial relationships
- Guide structure with mathematical precision
Together, they transform Stable Diffusion from a creative assistant into a precision instrument. You’re no longer hoping the AI understands your vision—you’re commanding exactly what you want, with repeatability and consistency that seemed impossible before.
Your next steps:
- Start with popular LoRAs on Civitai to learn how they affect your images
- Practice each ControlNet model separately before combining them
- Experiment with combinations to discover unique creative possibilities
- Build your personal library of favorite LoRAs and reference images
- Join the community on Reddit, Discord, and Civitai to share discoveries
The learning curve may seem steep, but each experiment teaches you more about these powerful tools. Every generation brings you closer to mastering the precise creative control that makes Stable Diffusion the choice of professionals worldwide.
Ready to dive deeper? Explore our complete guide to installing and using Stable Diffusion for more foundational techniques, or compare these features against other AI art platforms in our detailed comparison of Midjourney vs. Stable Diffusion’s advanced features.
Welcome to the world of precision AI art generation. Your masterpiece awaits.
Learn how to install and use LoRAs for style control and ControlNet for pose/composition control in Automatic1111. This guide provides a step-by-step process to master advanced image generation techniques for professional-quality results.
Total Time: 2 hours
Step 1: Install and Activate a LoRA for Style Control
First, download a LoRA file (with a .safetensors extension) from a repository like Civitai. Place this file into your stable-diffusion-webui/models/Lora folder. In the Automatic1111 interface, refresh your LoRA list and then add the syntax to your prompt to apply the specific style or character.
Step 2: Install the ControlNet Extension and Models
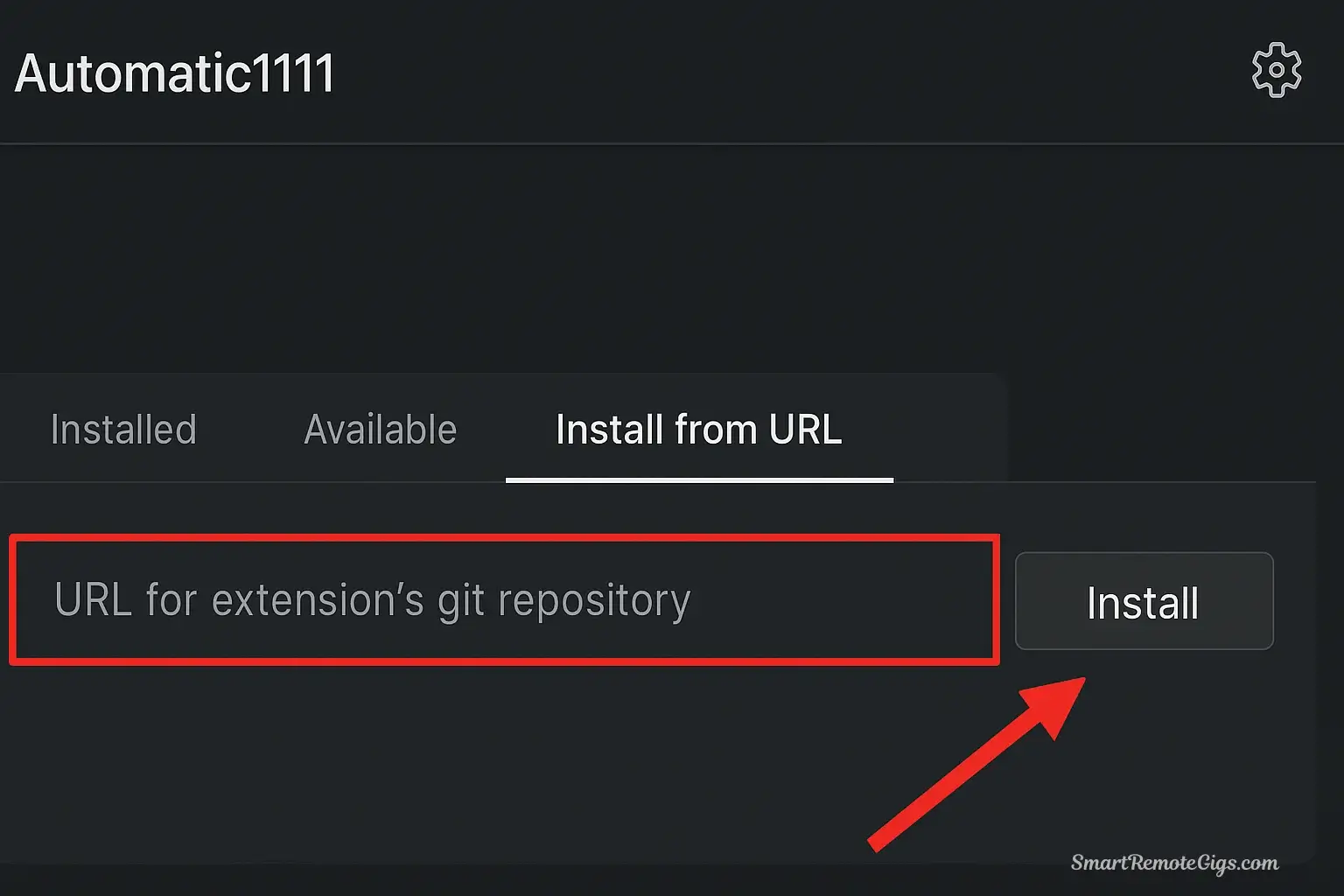
In the Automatic1111 Web UI, navigate to the “Extensions” tab and install the ControlNet extension from its official GitHub URL. After restarting the UI, download the necessary ControlNet models (e.g., control_openpose.pth) and place them into the extensions/sd-webui-controlnet/models folder.
Step 3: Use ControlNet for Precise Pose and Composition
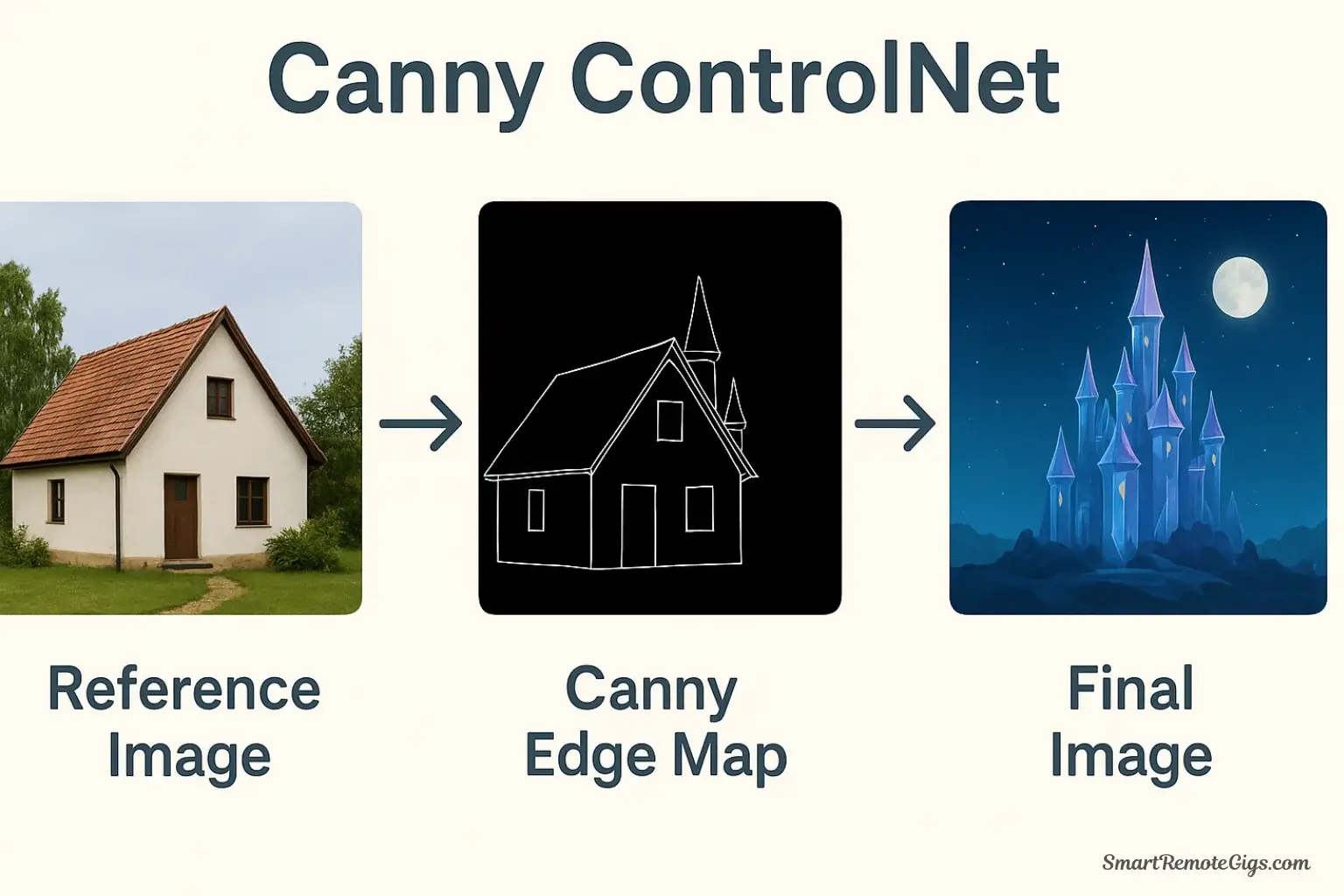
Below the main prompt area, expand the “ControlNet” section. Upload a reference image (e.g., a photo of a person in a specific pose). Select the appropriate Preprocessor (e.g., “OpenPose”) and its matching Model. Check the “Enable” box. Now, when you write your prompt, the generated character will precisely match the pose from your reference image.
Step 4: Combine LoRAs and ControlNet for Ultimate Control
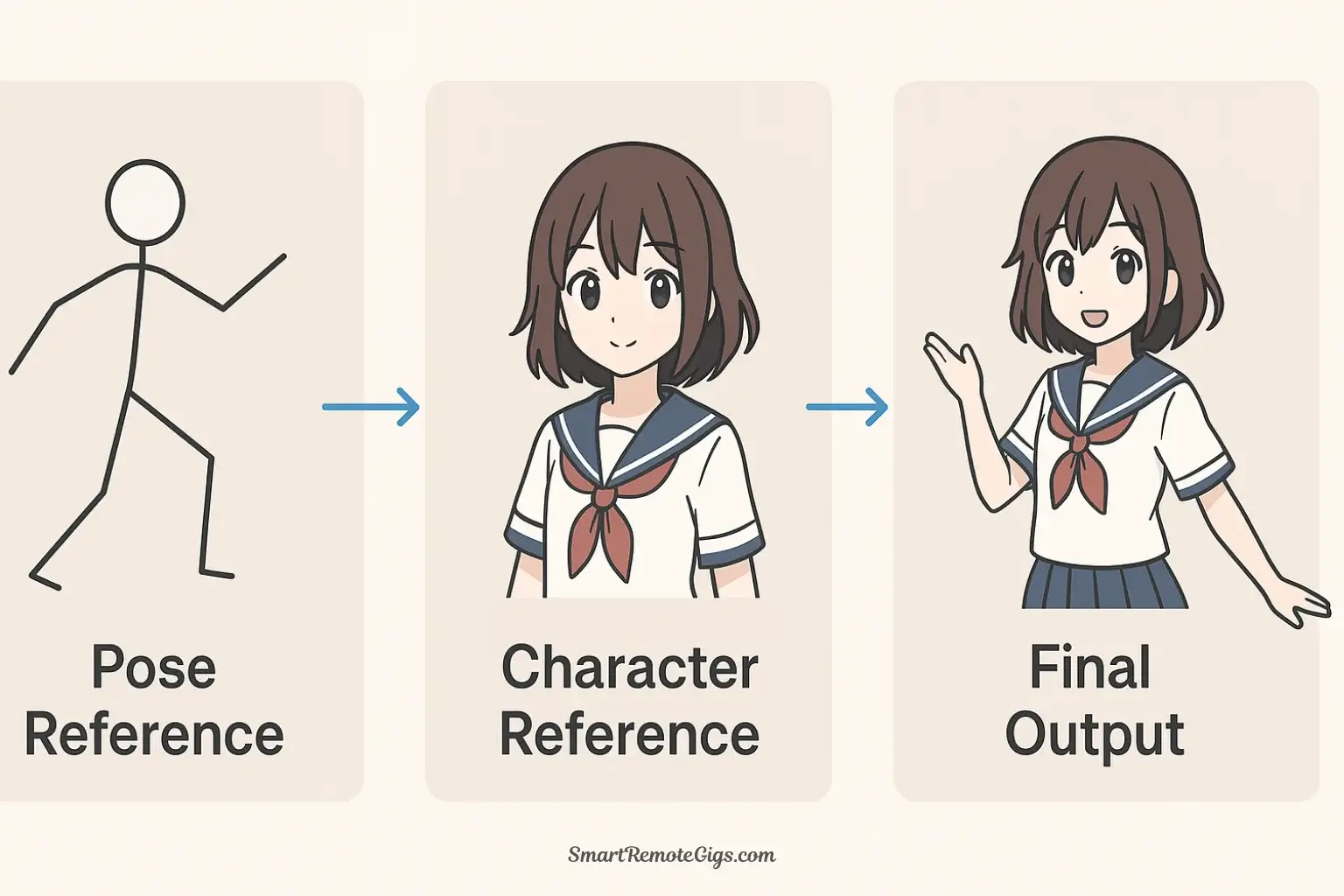
To achieve full mastery, combine both tools. First, set up your ControlNet as described in the previous step to lock in the image’s structure or pose. Then, in your main prompt, include a LoRA tag like to apply a specific art style or character onto that controlled structure. This gives you precise control over both what you generate and how it is composed.
Tools:
- A local installation of Stable Diffusion (e.g., Automatic1111)
- An internet connection
- A LoRA model file (e.g., from Civitai.com)
- A ControlNet model file (e.g., from Hugging Face)
- A reference image (for using ControlNet)