Why This Matters for Your Creative Work
Before we dive into the technical details, here’s the practical truth: the diffusion vs GANs debate isn’t just for computer scientists—the technology behind your AI image generator directly impacts how much control you have over the final output.
If you’re a freelancer, content creator, or designer using AI tools for client work, understanding which model powers your workflow affects:
- Prompt precision: How accurately your tool follows complex descriptions
- Consistency: Whether you can reliably recreate similar outputs
- Editing capabilities: Your ability to refine and adjust generated images
- Time management: How long you’ll wait for professional-quality results
The difference isn’t academic—it’s the difference between spending 2 hours fighting a tool that won’t follow your vision versus 20 minutes creating exactly what your client needs. Let’s break down the two competing technologies so you know what you’re working with.
GANs vs. Diffusion: Quick Comparison
Feature | GANs (The Artist & Critic) | Diffusion Models (The Sculptor) |
|---|---|---|
Core Method | Two networks compete to create/detect fakes | Gradually removes noise from a static image |
Speed | Fast (one-shot generation) | Slower (multi-step process) |
Image Quality | Good, but inconsistent | Excellent, highly coherent and detailed |
Training | Unstable, difficult to train | Very stable and reliable |
Prompt Control | Limited, struggles with text | Excellent, follows complex prompts |
Dominant Era | ~2014 – 2020 | ~2020 – Present |
Used By | Older models, specific research | Midjourney, DALL-E 3, Stable Diffusion |
GANs (Generative Adversarial Networks): The Artist and the Critic
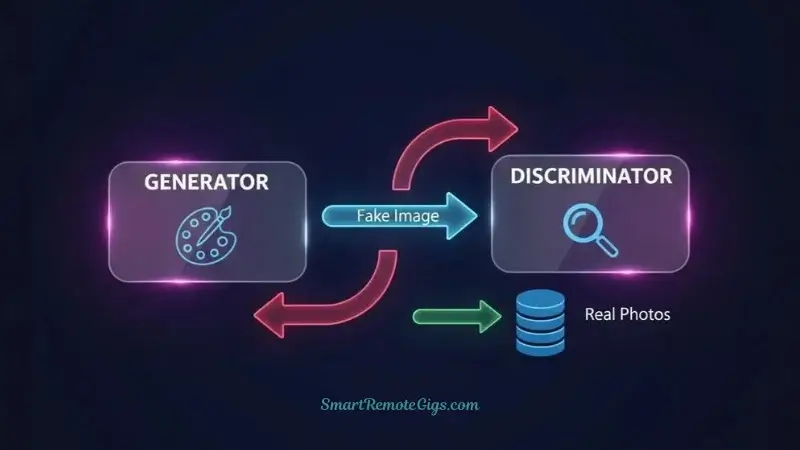
Imagine a talented but inexperienced artist trying to create perfect forgeries, working alongside an art critic who’s getting better and better at spotting fakes. This is essentially how Generative Adversarial Networks operate.
The Two-Player Game
GANs consist of two neural networks locked in an eternal competition:
The Generator (The Artist): This network tries to create images that look real. It starts by producing terrible, obvious fakes—like a child’s drawing trying to pass for a Picasso.
The Discriminator (The Critic): This network examines images and tries to determine whether they’re real (from a training dataset) or fake (generated by the artist). Initially, it’s easy to fool, but it quickly learns to spot the telltale signs of artificial images.
The Training Process
Here’s where the magic happens: As the critic gets better at spotting fakes, the artist is forced to improve to keep fooling it. The artist learns from each failure, gradually producing more convincing images. Meanwhile, the critic must constantly adapt to the artist’s improving skills.
Visual Process:
Generator → Creates Fake Image → Discriminator → "Real or Fake?"
↑ ↓
← Feedback: "Too obvious, try again" ← This adversarial training continues until the generator creates images so convincing that even the discriminator—now an expert fake-spotter—can’t tell the difference.
GANs in Practice
Ian Goodfellow’s original GAN paper introduced this concept in 2014, revolutionizing AI image generation. Early implementations produced groundbreaking results for their time.
GAN Strengths:
- Fast generation: Once trained, GANs can create images quickly
- Sharp, detailed outputs: When they work well, GANs produce crisp images
- Efficient sampling: Requires only a single forward pass to generate an image
GAN Weaknesses:
- Training instability: The two networks sometimes fail to balance, leading to training collapse
- Mode collapse: GANs may learn to generate only a limited variety of images
- Limited control: Difficult to direct the generation process with specific prompts
- Quality inconsistency: Results can vary dramatically in quality
Why GANs Struggle with Anatomy
One particularly visible limitation of GANs is their difficulty with complex anatomical details. The single-shot generation process doesn’t allow for iterative refinement, which is why GAN-based models often produced distorted hands and facial features. The adversarial training process simply couldn’t capture the nuanced complexity of human anatomy consistently.
Diffusion Models: The Sculptor and the Stone
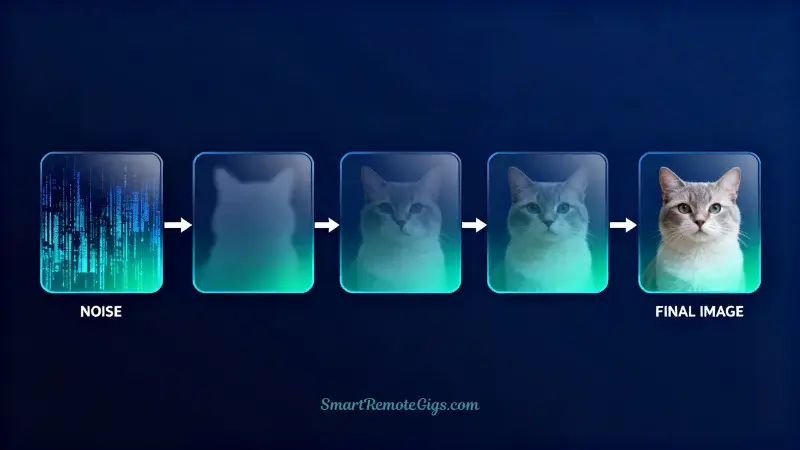
If GANs are like a competitive game between two players, diffusion models work more like a sculptor revealing a hidden statue within a block of marble. But instead of chiseling away stone, they’re carefully removing noise.
The Noise-to-Image Process
Diffusion models start with two key ingredients:
- Pure random noise (like television static)
- A text prompt describing what you want to create
The model then performs a series of “denoising” steps, gradually removing randomness while being guided by your prompt. It’s as if the AI can see the final image hidden within the noise and carefully reveals it, pixel by pixel.
The Step-by-Step Revelation
Visual Process:
Step 1: [Random Noise]
Step 2: [Slightly less noisy - vague shapes emerge]
Step 3: [Clearer forms - recognizable objects]
...
Step 50: [Final polished image]Unlike GANs, which generate images in one shot, diffusion models take dozens of small steps. Each step removes a little noise while adding details that match your prompt. This gradual process allows for remarkable control and consistency.
The Science Behind the Magic
The mathematical foundation involves training the model to predict and remove noise at each step. During training, the AI learns what “one step less noisy” should look like for millions of images. When generating new images, it applies this knowledge iteratively.
This process is rooted in the broader framework of modern AI image generation technology, where models learn patterns from data and use those patterns to create new, original content.
Diffusion Model Strengths:
- Exceptional quality: Produces highly detailed, coherent images
- Stable training: Much more reliable to train than GANs
- Diverse outputs: Generates varied results even with identical prompts
- Excellent prompt following: Superior at interpreting and following text descriptions
- Controllable generation: Allows for guided image creation and editing
Diffusion Model Weaknesses:
- Computationally intensive: Requires many steps, making generation slower
- Higher resource requirements: Needs more memory and processing power
- Complex implementation: More sophisticated architecture requires expertise
Pro Tip: How Inpainting Relies on Diffusion Technology
One of diffusion models’ most powerful features is inpainting—the ability to edit specific parts of an image while preserving the rest. This is only possible because diffusion models work step-by-step.
Here’s how it works: The AI adds noise only to the area you want to change, then runs the denoising process while keeping the rest of the image intact. This allows you to:
Replace objects in a scene (swap a red car for a blue one)
Fix anatomical errors (correct those infamous AI-generated hands)
Extend images beyond their borders (outpainting)
Refine specific details without regenerating everything
Practical Application: If you’re working on client projects and the AI generates 95% of what you need, inpainting lets you fix that 5% without starting over. GANs can’t do this—they’re all-or-nothing.
The Evolution of AI Art Technology
Understanding how we got from GANs to diffusion models reveals the rapid pace of AI advancement.
The GAN Era (2014-2020)
GANs dominated AI image generation for several years, producing increasingly impressive results:
- 2014: Original GANs generated tiny, blurry images
- 2016: Deep Convolutional GANs (DCGANs) produced clearer results
- 2018: Progressive GANs created high-resolution faces
- 2019: StyleGAN revolutionized controllable image generation
These developments were impressive but came with significant limitations. Training GANs remained challenging, and generating images from text descriptions was particularly difficult.
The Diffusion Revolution (2020-Present)
The introduction of diffusion models marked a turning point:
- 2020: The landmark paper on Denoising Diffusion Probabilistic Models (DDPMs) demonstrated a new path to superior image quality, kicking off the revolution
- 2021: Latent Diffusion Models, the basis for Stable Diffusion, made the approach computationally feasible by working in a compressed latent space
- 2022: DALL-E 2, Midjourney, and Stable Diffusion brought diffusion models to mainstream audiences
- 2023-Present: Continued refinements in speed, quality, and control
Latent Diffusion: The Best of Both Worlds
Modern diffusion models like Stable Diffusion use a clever optimization called “latent diffusion.” Instead of working directly with full-resolution images (which would be computationally prohibitive), they work in a compressed “latent space” and then decode the result back to a full image.
This approach combines the quality advantages of diffusion with more manageable computational requirements, making high-quality AI art generation accessible to broader audiences.
Which Technology Won?

While GANs paved the way and remain useful for specific applications, diffusion models have become the dominant technology for modern AI art generation.
The victory is so decisive that the industry is now extending diffusion technology beyond static images—tools like OpenAI’s Sora and the next-generation Runway Gen-3 are applying the same step-by-step denoising approach to video generation, proving that diffusion models represent the future of all visual AI content creation.
Why Diffusion Models Dominate
1. Superior Image Quality: Diffusion models consistently produce higher-quality, more coherent images across a wider range of subjects and styles.
2. Better Text Understanding: The step-by-step generation process allows for better interpretation of complex text prompts, making tools like Midjourney and DALL-E 3 possible.
3. Training Stability: Diffusion models are much easier to train reliably, leading to more consistent results and faster development cycles.
4. Controllability: The iterative nature of diffusion allows for more precise control over the generation process, enabling features like image editing and style transfer.
Current Platform Technologies
- Midjourney: Uses advanced diffusion models optimized for artistic quality and aesthetic appeal
- DALL-E 3: Built on OpenAI’s improved diffusion architecture with enhanced text understanding
- Stable Diffusion: Open-source diffusion model that has spawned countless variations and applications
- Adobe Firefly: Uses diffusion models trained specifically on commercially-licensed content
GANs Still Have Their Place
While diffusion models dominate consumer AI art tools, GANs remain valuable for specific applications:
- Real-time generation: Where speed is more important than quality
- Style transfer: For specific artistic effects and transformations
- Research applications: Exploring new approaches to generative modeling
- Specialized domains: Where the training requirements favor GAN architectures
Understanding the Impact on Your Creative Process
Knowing whether your preferred AI tool uses GANs or diffusion models can help you understand its capabilities and limitations.
Diffusion Model Expectations
If you’re using Midjourney, DALL-E 3, or Stable Diffusion:
- Expect high quality: These tools consistently produce detailed, coherent images
- Be patient: Generation takes time (typically 10-60 seconds)
- Experiment with prompts: These models excel at interpreting complex descriptions
- Explore variations: Each generation will be unique, even with identical prompts
Optimizing Your Workflow
Understanding diffusion models can improve your results:
Detailed Prompts Work Better: Unlike earlier GANs, diffusion models can handle and benefit from detailed, specific descriptions.
Iterative Refinement: The step-by-step nature means you can often guide the process through careful prompting.
Quality Over Speed: These tools prioritize image quality, so patience yields better results.
The Future of AI Art Technology
Both GANs and diffusion models continue to evolve, with researchers exploring hybrid approaches and entirely new methods.
Emerging Developments
- Consistency Models: Aim to combine diffusion quality with GAN speed
- Multimodal Integration: Better integration of text, images, and other data types
- Real-time Diffusion: Optimizations making diffusion models faster for interactive use
- Specialized Architectures: Models designed for specific creative tasks or industries
According to recent research from Google DeepMind, next-generation models are achieving real-time performance while maintaining diffusion-level quality.
What This Means for Users
As these technologies continue to advance, expect:
- Faster generation: Even diffusion models will become more responsive
- Better control: More precise ways to direct the creative process
- Higher quality: Continued improvements in detail and coherence
- New capabilities: Features we haven’t yet imagined becoming possible
From Competition to Creation
Understanding the technology behind AI art generation reveals the incredible innovation driving this creative revolution. GANs introduced the concept of AI-generated images through their ingenious adversarial training, while diffusion models refined the approach to achieve unprecedented quality and control.
Today’s most popular AI art tools—from Midjourney’s artistic interpretations to DALL-E 3’s precise prompt following—all build upon the foundation of diffusion model technology. This iterative, step-by-step approach to image generation has proven superior for creating the diverse, high-quality images that have captured our collective imagination.
Whether you’re a professional artist, content creator, or curious experimenter, appreciating these underlying technologies can deepen your understanding of what’s possible and help you make the most of these remarkable creative tools. The next time you watch an AI transform your words into a stunning image, you’ll know you’re witnessing the result of years of research into making machines truly creative partners.
Ready to Put This Knowledge Into Practice?
Now that you understand the engine, it’s time to see these diffusion models in action. Our comprehensive guide covering the 12 best free AI image generators showcases these technologies at work. And to maximize your results, learning how to write effective AI art prompts will teach you how to speak the language of diffusion models.
Have questions about GANs vs. Diffusion models? Drop them in the comments below!